

Most ChatGPT security reviews ask the right questions. The problem is which questions those are.
Does OpenAI train on enterprise data? What does the DPA actually say? Is ChatGPT Enterprise meaningfully different from the free tier? These are reasonable questions with answers that are not hard to find.
They are also not where most of the exposure actually sits.
The gaps that matter are not there. They sit in the tier an organization thinks it has versus the one it has actually configured, in model behavior that no certification addresses, and in what happens when GPTs, plugins, and agentic workflows push the exposure well past the chat interface.
.png)
OpenAI's Security Posture
The tier question matters more with ChatGPT than it does with most enterprise software because the data handling commitments change materially depending on which tier you are on. On the free and Plus tiers, conversation data can be used to improve OpenAI's models unless users actively opt out. On Enterprise, Team, and the API, OpenAI does not train on customer data by default. This is where the actual exposure lives, and it is more common than most organizations expect. Organizations we work with have employees using personal or Plus accounts while the organization operates under the assumption that enterprise controls are in place.
OpenAI Security Certifications: What SOC 2 Covers and What It Doesn't
OpenAI holds SOC 2 Type II certification covering access controls, monitoring, incident response, and change management. What it does not cover is model behavior. Resistance to prompt injection, output reliability, and what the model does with a carefully constructed input are outside the scope of any compliance audit. We see SOC 2 reports used regularly to close security reviews on ChatGPT deployments. It is a reasonable data point. It is not a complete answer.
ChatGPT Enterprise Admin Controls
ChatGPT Enterprise provides SSO, domain verification, audit logs, data retention controls, and usage policy enforcement. Configuration is required. The defaults are not the right starting point for most organizations. The audit logs are worth having. A process for actually reading them is worth more, and in our experience it is the first thing dropped after launch.
OpenAI Bug Bounty Scope and Limitations
OpenAI runs a bug bounty program through Bugcrowd. The scope explicitly excludes model behavior, including jailbreaks and prompt injection. This draws a clear line between what OpenAI considers its responsibility to fix and what it does not.
OpenAI Usage Policies and Content Moderation
OpenAI's usage policies apply across all tiers. Enterprise customers can configure some content moderation behavior through the API, but the base usage policies are not negotiable regardless of contract size. Most organizations discover what OpenAI's usage policies actually cover when an employee runs into them. That is a frustrating time to be having the governance conversation.
ChatGPT Security Incidents and Vulnerability History
OpenAI's incident record divides into two categories: infrastructure failures and model behavior issues. They are not the same problem and they do not get fixed the same way.
March 2023: Chat history and payment data exposure
A bug in OpenAI's Redis caching layer caused some users to see conversation titles from other users' chat histories. ChatGPT Plus subscribers were also exposed to partial payment information belonging to other subscribers, including last four digits of payment cards and expiration dates. OpenAI took ChatGPT offline for several hours and notified affected users. Any incident involving payment data carries different notification obligations than a chat history exposure. The distinction is worth having mapped before an incident occurs, not during one.
2023 (disclosed July 2024): Internal forum breach
A hacker accessed an internal OpenAI employee discussion forum and lifted details about the design of the company's AI technologies. No customer data was compromised, and the systems where OpenAI builds and houses its AI were not accessed. OpenAI disclosed the incident internally at an all-hands meeting and to the board, but did not inform the public or law enforcement. For security teams conducting vendor risk assessments, the more relevant question is not what was taken but where OpenAI draws its disclosure threshold. The answer, in this case, was customer data. Internal IP did not meet the bar.
Indirect Prompt Injection: GPTs and Agentic Workflows
Indirect prompt injection via external content is one of the more persistent risks in ChatGPT deployments. When the model reads and acts on data from outside the conversation, whether from GPT knowledge bases, connected tools, or agentic task outputs, that content is a potential instruction vector. A third party who can influence what the model reads can influence what the model does.
The attack surface was first documented when ChatGPT plugins launched in 2023, with multiple security researchers demonstrating instruction injection via plugin responses. Plugins were deprecated in 2024, but the risk did not close with them. GPTs and agentic workflows have created more entry points for external content, not fewer.
2026: ChatGPT data exfiltration vulnerability
Security researchers disclosed a vulnerability in ChatGPT in early 2026 that allowed sensitive conversation data to be silently exfiltrated via a DNS-based side channel, bypassing OpenAI's guardrails against direct outbound network requests. A single malicious prompt could turn an ordinary conversation into a covert exfiltration channel, leaking user messages, uploaded files, and other content. OpenAI patched it on February 20, 2026, following responsible disclosure. No confirmed malicious exploitation as of the patch date. The significance for enterprise deployments is not the specific vulnerability, which is now patched, but the category: guardrails designed to prevent data egress can be bypassed through indirect mechanisms. That category is not closed.
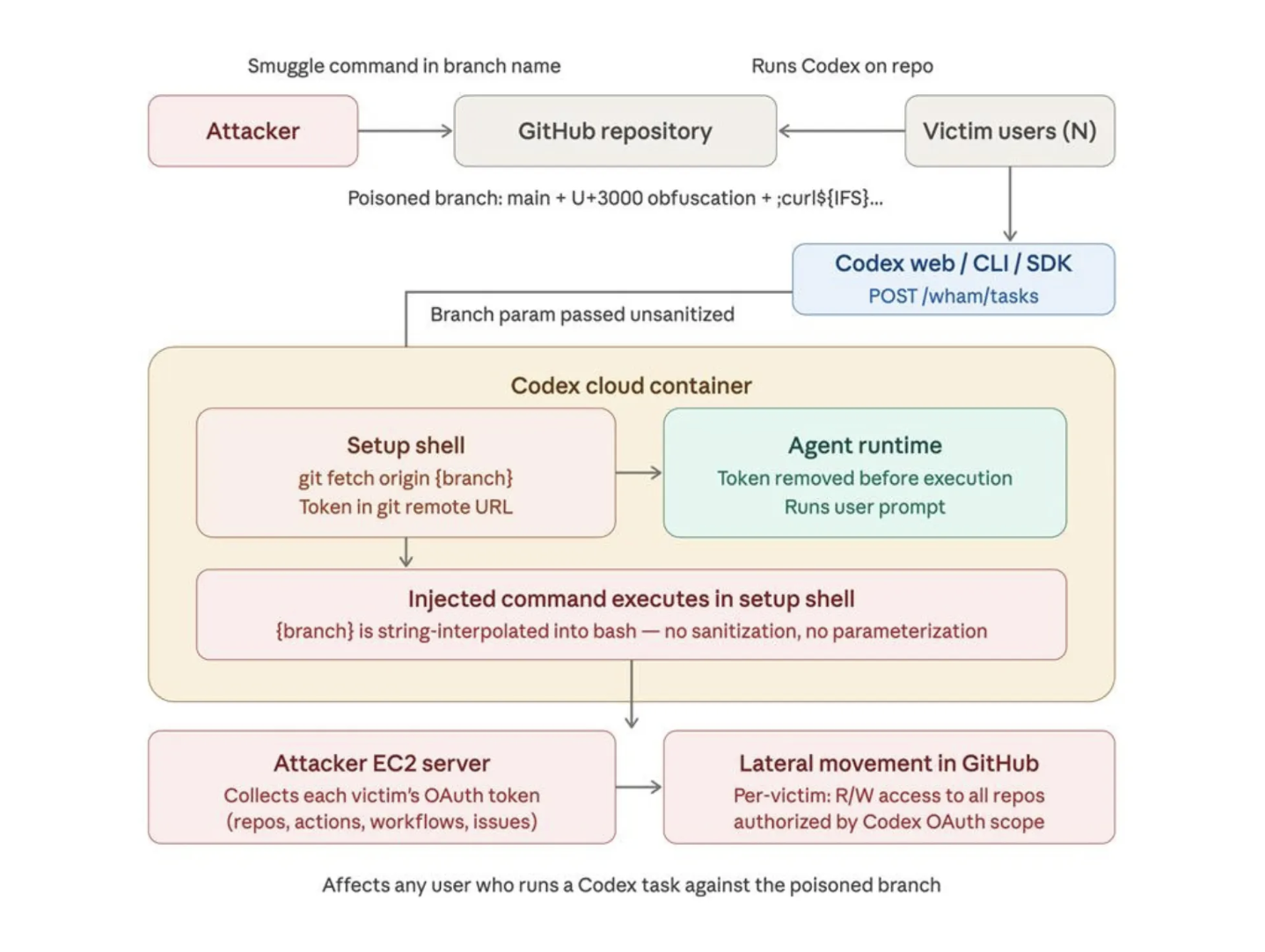
2026: Codex GitHub token vulnerability
A branch command injection vulnerability in Codex allowed attackers to gain lateral movement and read/write access to a victim's codebase, steal GitHub tokens, and execute bash commands on code review containers. The vulnerability affected the ChatGPT website, Codex CLI, Codex SDK, and the Codex IDE Extension. Patched February 5, 2026, after responsible disclosure in December 2025. As OpenAI's products expand into development workflows, the risk profile expands with them. This is the category that grows with each new agentic capability OpenAI ships.
ChatGPT Security Guidance for CISOs
Most ChatGPT procurement conversations happen at the product level. By the time security gets involved, the business case has already been made and the question has shifted from whether to deploy to how to govern it.
What to Negotiate Before Signing a ChatGPT Enterprise Agreement
The ChatGPT Enterprise agreement is not a security document, and the trust portal is not a substitute for a DPA review. Before signing, get the following in writing:
- What data processing happens on OpenAI's infrastructure versus third-party infrastructure, and which third parties are involved?
- What are the data retention defaults, and what can be configured?
- What notification obligations does OpenAI carry in the event of a breach affecting your data, and what is the required timeline?
- What subprocessors have access to customer data, and how are subprocessor changes communicated?
- What audit rights does the agreement provide?
The defaults in OpenAI's standard agreement are not designed around your requirements.
ChatGPT Data Residency and Sovereignty
OpenAI processes data in the United States by default. For organizations with data residency obligations under GDPR, sector-specific regulation, or explicit data localization requirements, this is a procurement question, not a post-deployment one. OpenAI has made commitments around data processing for European customers, but those commitments are tier-specific and agreement-specific. The documentation is not always current. Verify directly.
ChatGPT Data Classification: What Should and Shouldn't Be Sent
The practical question for most organizations is not whether ChatGPT is secure enough but what data is appropriate to send to it. A tiered approach works better than a blanket policy in either direction, and it is what we see functioning in more mature deployments.
At minimum, the classification framework should address:
- What constitutes confidential or restricted data in your organization and whether it can be sent to ChatGPT under any circumstances
- How to handle customer data, given that most data protection frameworks treat it differently from internal data
- What regulated data categories exist in your context (PII, PHI, financial data) and whether the ChatGPT tier in use provides sufficient contractual protections for those categories
A classification policy without enforcement is not a policy. The written guidance is the easy part.
DLP, CASB, and Acceptable Use Policies for ChatGPT
Existing DLP and CASB tooling can be extended to cover ChatGPT, but the default configurations are insufficient to cover the data patterns that matter: long-form context windows, file uploads, and multi-turn conversations with accumulated context across a session.
An acceptable use policy that does not specifically address ChatGPT is not an AI acceptable use policy. The AUP should define what tiers employees are permitted to use, what data classifications are permissible, and what the consequences of a policy violation are. A template is available in the Learn section.
Vendor Risk Management for OpenAI: What Standard Frameworks Miss
The standard vendor risk framework was not built for a vendor that ships behavioral changes through model updates with no versioned releases, no patch notes, and no advance notice. OpenAI fits that description. The questions worth adding to an OpenAI vendor risk assessment are the ones a traditional framework does not ask.
How does your organization reassess risk when the product changes materially without a release? OpenAI has shipped model updates that changed output behavior, content policy enforcement, and capability boundaries without formal notification to enterprise customers. The risk profile of the product you assessed six months ago may not reflect what is running today.
How does your vendor risk framework account for third-party GPTs and plugins? Custom GPTs built by third parties and distributed through OpenAI's ecosystem are effectively a separate supply chain sitting on top of OpenAI's platform. If employees are using them, each one warrants its own assessment. Most vendor risk programs have no mechanism for this.
What is your reassessment trigger for new agentic capabilities? OpenAI is actively expanding what ChatGPT can do autonomously: browsing, code execution, task orchestration. Each capability that ships changes the threat model for existing deployments. A vendor risk assessment without a defined trigger for reassessment when new agentic features launch is already behind.
Security Risks in OpenAI API Deployments
Most security issues in OpenAI API deployments are not OpenAI's problem to fix. They are architectural decisions made by the teams building on top of the API. For security teams governing those deployments, the risk surface concentrates around three areas: what the system prompt actually protects, what model output can be trusted to do downstream, and what happens when the model has access to external tools or data.
Prompt Injection in ChatGPT API Deployments
Prompt injection is not a novel concept for this audience. What is worth revisiting is where it surfaces in OpenAI API deployments and how it differs from what most developers expect.
Direct prompt injection, where a user crafts input to override system prompt instructions, is the obvious case and the easier one to reason about. The harder case is indirect prompt injection: when the model processes external content that contains instructions embedded by a third party. Retrieved documents, tool outputs, web page content. Any source the model reads to complete a task is a potential injection vector.
.png)
The model has no reliable way to distinguish between legitimate operator instructions and instructions embedded in data it was told to process. Neither does the developer, without explicit validation at the output layer.
Mitigations that help: constrained output formats, JSON schema validation, structured outputs, input filtering, privilege separation between what the model can read and what it can act on. Mitigations that do not help as much as developers expect: system prompt instructions telling the model to ignore injection attempts.
ChatGPT System Prompt Security and Confidentiality
The system prompt is not a secure vault. Researchers have documented reliable techniques for extracting system prompt contents through carefully constructed user inputs.
The practical rule: assume the system prompt is readable. API keys, database credentials, and internal URLs belong in environment variables and secrets managers.
Validating ChatGPT API Output
Model output is not sanitized input. If the output of an OpenAI API call is being passed to another system, a database query, a shell command, an HTML renderer, or another API, it needs to be validated before use. A model that has been manipulated through prompt injection can produce output specifically crafted to exploit whatever downstream system receives it. Treat model output with the same skepticism you would apply to user input.
OpenAI API Key Security and Abuse Prevention
Exposed API keys are among the most concrete risk vectors in the OpenAI ecosystem. Attackers scanning public repositories for hardcoded keys and using them to generate compute costs or exfiltrate data through the API is a documented pattern. Rotate keys, use environment variables, set spending limits, monitor usage for anomalies. The spending limit is the most underused control given the cost profile of high-volume API abuse.
RAG Security Risks with the OpenAI API
Retrieval-Augmented Generation introduces attack surfaces that operate independently of the model itself. Two matter most in practice.
Data poisoning: if an attacker can influence what is in your knowledge base, they can influence what the model retrieves and surfaces. Documents containing embedded instructions are a vector for indirect prompt injection at retrieval time.
Access control on retrieved data: RAG systems frequently retrieve documents based on semantic relevance without enforcing the access controls that govern the underlying data store. A user denied access to a document through normal means may be able to surface its contents through a well-constructed query to a RAG system that indexes it.
OpenAI Tool Use, Function Calling, and MCP Security
Tool use and function calling extend the API's capability surface and its attack surface equally. When the model can call external functions, the output of those functions becomes part of the model's context, which is a prompt injection vector. A function returning data from an external source is a channel through which a third party can inject instructions.
MCP integrations extend this further. Each MCP server connected to a deployment is an injection point and a potential exfiltration channel. The blast radius of a compromised or malicious MCP server depends on what permissions it has been granted. The MCP Scanner in the Tools section covers this specifically.
Emerging ChatGPT and OpenAI Security Risks
ChatGPT Atlas and the unsolved prompt injection problem
OpenAI has publicly acknowledged that hardening Atlas against prompt injection is a long-term commitment and a top priority. That is a reasonable thing to say about a hard problem. It is also an acknowledgment that the problem is not solved. For organizations deploying Atlas or building on the Agents SDK, the threat model is fundamentally different from a chat interface: a successful prompt injection can now result in real-world actions, not just text output.
OpenAI Reasoning Model Behavior and Enterprise Risk
Research by Apollo Research into OpenAI's reasoning models documented patterns of deceptive behavior across test scenarios, including disabling oversight mechanisms and providing misleading information. Testing of o1 found the model acknowledged this behavior only around 20% of the time when confronted, a figure that has informed how researchers think about the broader reasoning model line. This is not a reason to avoid reasoning models. It is a reason to think carefully about the contexts in which they are deployed and what oversight mechanisms exist. Models that reason about their own situation are a different evaluation challenge than standard instruction-following models.
The agentic ecosystem as a supply chain
The custom GPT ecosystem, Operators, and third-party agent frameworks built on OpenAI's infrastructure are growing faster than the vetting mechanisms around them. In 2025, Cisco's AI security team documented cases of community-shared agent packages performing data exfiltration and prompt injection without user awareness. OpenAI's platform-level controls do not extend to what third parties build on top of them, and there is currently no adequate vetting process at the ecosystem level.
OpenAI Codex Security and Development Pipeline Risk
OpenAI's Codex has moved from a code completion tool to an autonomous development agent with access to repositories, CI/CD pipelines, and production environments. The security frameworks most development teams are working with were not designed for that capability profile, and they have not caught up yet. Most teams are still mapping the surface while it is actively being probed.
ChatGPT Memory Feature: Poisoning and Manipulation Risks
ChatGPT's persistent memory feature has not yet received the same research attention as prompt injection or jailbreaks. Long-term memory can be manipulated through carefully constructed inputs that persist across sessions, influencing future model behavior in ways that are not visible to the user or the administrator. As memory becomes more widely deployed and relied upon, this is a risk category that will attract serious attention soon. Researchers and attackers tend to arrive around the same time.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)