
AI Red Teaming: Uncover AI risks and vulnerabilities in your Homegrown AI Apps
From discovery to remediation to runtime protection, Prompt Security’s Automated AI Red Teaming identifies critical risks like prompt injection, data exposure, and unsafe agent behavior, with actionable reports and clear remediation guidance.
What is AI Red Teaming?
From discovery to remediation to runtime protection, Prompt Security’s Automated AI Red Teaming identifies critical risks like prompt injection, data exposure, and unsafe agent behavior, with actionable reports and clear remediation guidance.
Proactive AI Risk Assessment for AI-Specific Risks
Automatically test homegrown AI applications against AI risks such as prompt injection, jailbreaks, data exposure, harmful content, and unsafe agent behavior. Purpose-built for the nondeterministic nature of LLMs.
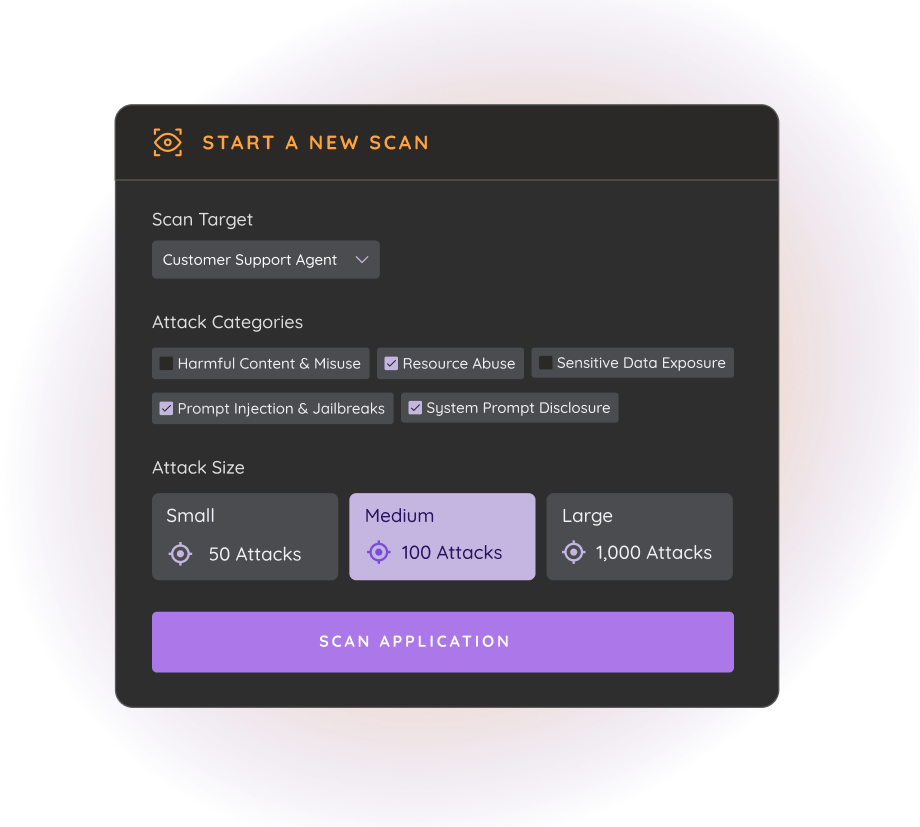
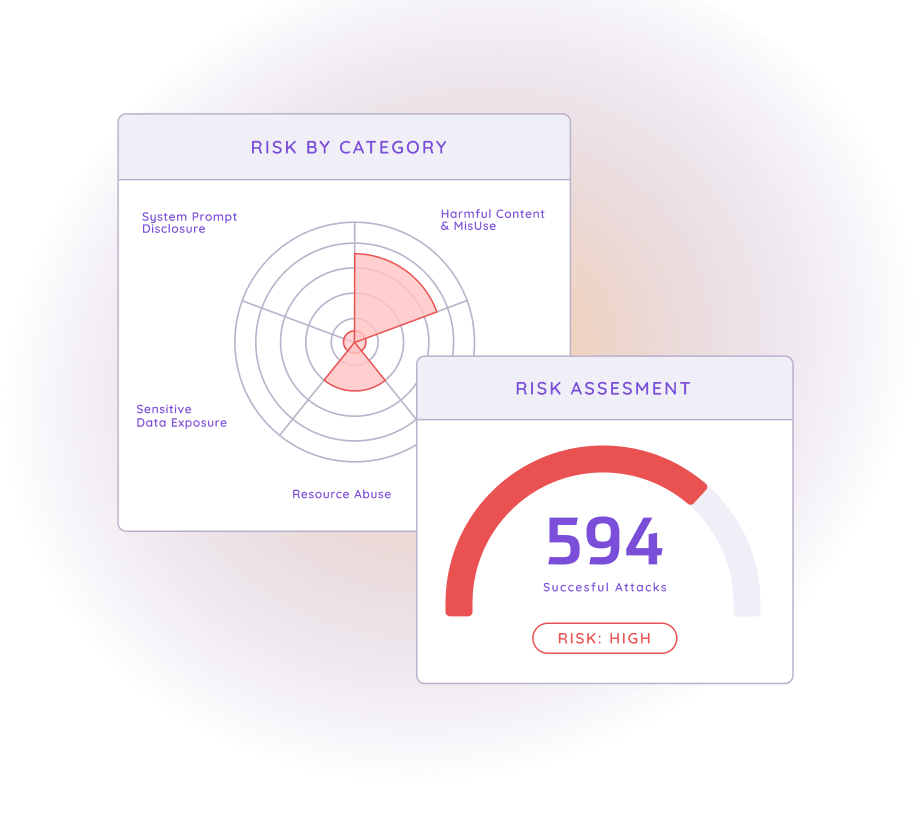
Harden AI Applications from Pre-Prod to Runtime
Run pre-production red teaming, prioritize issues using risk scoring and evidence, and confidently ship production-ready AI applications. Maintain continuous evaluations that detect drift over time.
Actionable Remediation at
AI Speed and Scale
Get clear findings with remediation recommendations. Seamlessly pair them with Prompt Security’s Homegrown AI Application protection to move from exposure discovery to runtime protection.


